Machine Learning Overfitting vs Underfitting: 4 Proven Fixes for Beginners

Overfitting vs Underfitting in Machine Learning: What Nobody Tells You
A friendly, no-fluff guide to understanding overfitting vs
underfitting in machine learning — the two mistakes that
silently kill most beginners’ first models- with fresh analogies, the bias-variance tradeoff explained simply, and actual Python fixes.
You just trained your first Machine Learning model. The accuracy on your training data? 98%. You’re feeling like a genius. You submit it. The test accuracy comes back: 61%.
You stare at the screen. What went wrong? The model looked so good. Your data was clean. Your code was right.
Chances are, you just met the two most common monsters in machine learning: overfitting and underfitting. And almost every beginner runs into them. This post will help you understand them, detect them, and actually fix them — no textbook jargon, I promise.
What is Overfitting?
Imagine you’re preparing for a cooking competition. Instead of learning cooking techniques, you memorize exactly what the last 10 judges ordered — down to the exact amount of salt, the specific garnish, even the order of courses. You’re not learning to cook. You’re learning to reproduce.

Day of the competition: different judges. They want different dishes. You’re lost.
That’s overfitting in machine learning. Your model has memorized the training data so thoroughly — including its quirks, its noise, its outliers — that it has zero ability to generalize to new, unseen data.
🔴 Overfitting in one line
Your model performs great on training data but crashes on test data. It’s a memorizer, not a learner.
Technically: the model has learned the noise in your training set as if it were a real pattern. High training accuracy + low test accuracy = overfitting alarm bells.
What is Underfitting?
Now imagine a completely different student. They show up to the cooking competition having only watched one YouTube video titled “Cooking Basics”. They know how to boil water. That’s it.
Every dish they make? Boiled. The pasta? Boiled. The dessert? Also somehow boiled. They’re not learning the task — they’re applying one oversimplified rule to everything.

That’s underfitting in machine learning . Your model is too simple to capture the actual patterns in the data. It fails on both training data and test data.
🟢 Underfitting in one line
Your model is too dumb (simple) to understand the data. Low accuracy everywhere — it hasn’t actually learned anything useful.
What Does This Look Like Visually?
Picture you’re fitting a curve through some data points. Here’s what each scenario looks like:
Model Fit Comparison
Underfitting
Too simple — misses the real pattern
Just Right
Captures the pattern, generalizes well
Overfitting
Passes through every point — learns noise
The underfit model draws one straight line through everything — it’s too simple. The overfit model twists and turns to hit every single data point, including the noisy outliers. The just-right model captures the general trend without obsessing over individual points.
The Bias-Variance Tradeoff (Without the Math)
This is the concept that ties everything together. Don’t worry — no scary equations here.
High Bias
Your model makes strong assumptions about the data and consistently gets things wrong in the same direction. It’s systematically off. This causes underfitting.
High Variance
Your model is too sensitive — small changes in training data cause huge changes in the model. It’s inconsistent and unreliable on new data. This causes overfitting.
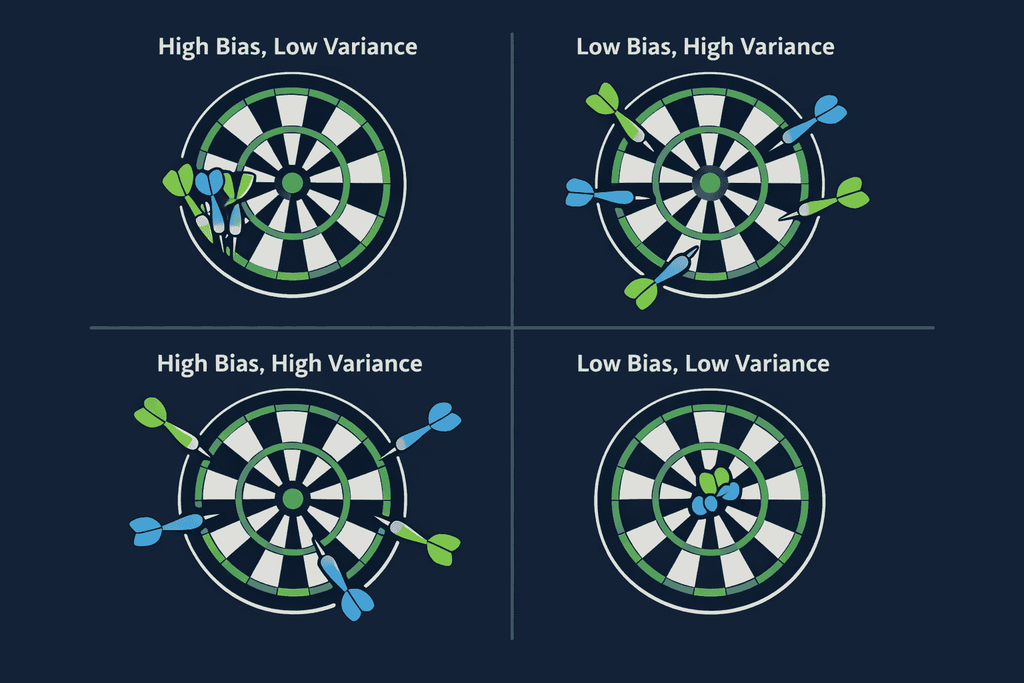
Think of it like this: imagine you’re throwing darts at a bullseye.
High bias, low variance = all your darts land together — but far from the center. Consistent, but consistently wrong.
Low bias, high variance = your darts are scattered all over the board. Sometimes you hit the bullseye, sometimes you miss by a mile.
Low bias, low variance = all your darts cluster near the center. That’s the goal.
⚡ The Tradeoff
As you make a model more complex (to reduce bias), it tends to increase variance. Your job is to find the sweet spot — complex enough to learn the pattern, simple enough to not memorize the noise.
How to Detect Overfitting and Underfitting in machine learning
Signs of Overfitting in machine learing
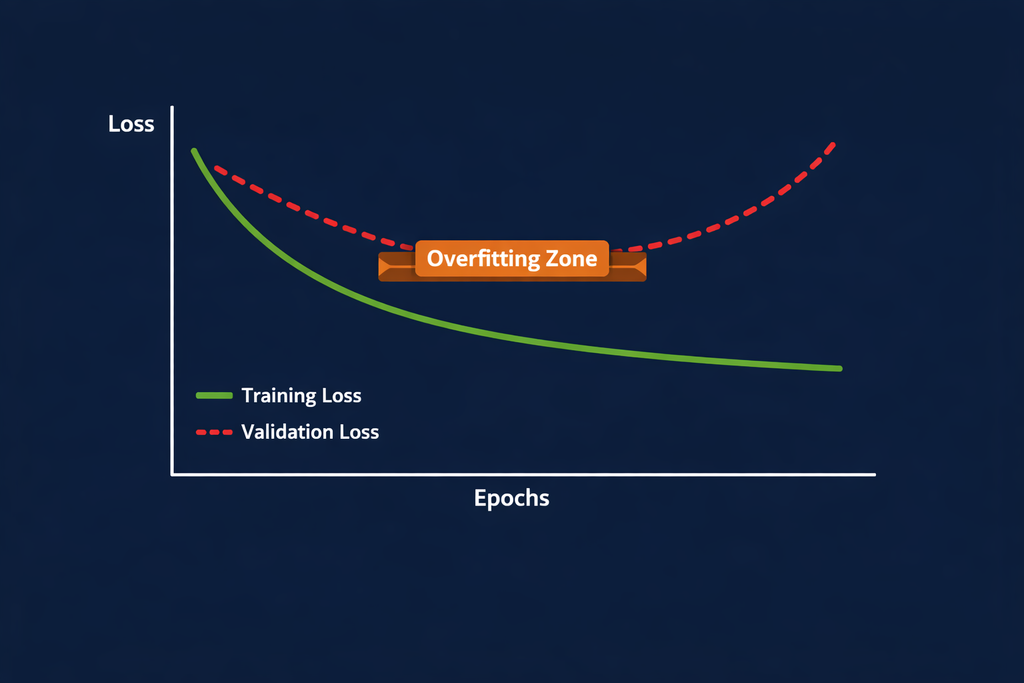
— Training accuracy is very high (98%, 99%), but test/validation accuracy is much lower (60–70%)
— Large gap between training loss and validation loss as training progresses
— Model performance degrades noticeably on new real-world data
Signs of Underfitting in machine learning
— Both training and test accuracy are low — the model is failing everywhere
— Loss barely decreases even as you train for more epochs
— Model gives the same or near-same prediction for very different inputs
| Metric | Underfitting | Good Fit | Overfitting |
|---|---|---|---|
| Training Accuracy | Low | High | Very High |
| Test Accuracy | Low | High | Low |
| Train-Test Gap | Small | Small | Large |
| Bias | High | Balanced | Low |
| Variance | Low | Balanced | High |
How to Fix Overfitting
Great — you’ve diagnosed overfitting. Here’s your toolkit:
1. Regularization (L1 / L2)
Regularization adds a penalty to the model for having large coefficients — it basically forces the model to stay simpler. L2 (Ridge) is the most common.
Python · sklearn · Ridge Regression
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# alpha controls regularization strength — higher = simpler model
model = Ridge(alpha=1.0)
model.fit(X_train, y_train)
print("Train Score:", model.score(X_train, y_train))
print("Test Score :", model.score(X_test, y_test))
2. Dropout (for Neural Networks)
Dropout randomly “turns off” neurons during training, forcing the network to learn robust features rather than memorizing specific paths.
Python · Keras · Dropout Layer
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
model = Sequential([
Dense(128, activation='relu'),
Dropout(0.3), # drop 30% of neurons during training
Dense(64, activation='relu'),
Dropout(0.3),
Dense(1, activation='sigmoid')
])
3. More Training Data / Data Augmentation
The more diverse your training data, the harder it is for the model to memorize it. If you can’t collect more data, try augmentation — flipping images, adding noise, etc.
4. Early Stopping
Python · Keras · Early Stopping
from tensorflow.keras.callbacks import EarlyStopping
early_stop = EarlyStopping(
monitor='val_loss',
patience=5, # stop if val_loss doesn't improve for 5 epochs
restore_best_weights=True
)
model.fit(X_train, y_train,
validation_split=0.2,
epochs=100,
callbacks=[early_stop])
How to Fix Underfitting
Underfitting usually means your model is too simple for the problem. Here’s how to level it up:
1. Use a More Complex Model
Python · sklearn · Random Forest (more powerful than linear models)
from sklearn.ensemble import RandomForestClassifier
# More estimators + deeper trees = more complexity
model = RandomForestClassifier(
n_estimators=200,
max_depth=None, # let trees grow fully
min_samples_split=2
)
model.fit(X_train, y_train)
2. Add More Features
If your model can’t find patterns, maybe you’re not giving it enough information. Try feature engineering — creating new features from existing ones.
Python · sklearn · Polynomial Features
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LinearRegression
pipeline = Pipeline([
('poly', PolynomialFeatures(degree=3)), # add x², x³ features
('model', LinearRegression())
])
pipeline.fit(X_train, y_train)
3. Reduce Regularization
If you’re already using regularization and your model is underfitting, dial it down. A lower alpha in Ridge/Lasso means less penalty, more freedom for the model to learn.
Real World Example: Predicting House Prices
Say you’re building a model to predict house prices using features like area, number of rooms, and location.
Underfitting in machine learning scenario: You use a simple linear regression with just “area” as a feature. It predicts a 3BHK and a 1BHK of the same area as the same price. Clearly wrong — the model is missing important patterns.
Overfitting in machine learning scenario: You use a deep decision tree with no depth limit. On your 200-row training set, it achieves 99% accuracy by essentially memorizing each house. You test it on 50 new houses — accuracy drops to 58%. It learned the quirks of your 200 houses, not the general market.
Just right: A Random Forest with proper depth limits, cross-validation, and feature engineering (area × rooms, location category, etc.). It captures real patterns and generalizes well to new data.
💡 Key Takeaway
The goal of Machine Learning is never to build a model that’s perfect on your training data. It’s to build one that understands the problem well enough to handle data it’s never seen. That’s the real definition of a good model.
❓ FAQs
Q1. What is the main difference between overfitting and underfitting in machine learning? Overfitting happens when a model learns the training data too well — including its noise — and fails to generalize to new data (high training accuracy, low test accuracy). Underfitting happens when a model is too simple to capture the data’s patterns, resulting in poor performance on both training and test sets. Think of overfitting as memorization and underfitting as not studying enough.
Q2. How does the bias-variance tradeoff relate to overfitting and underfitting in machine learning? Underfitting is caused by high bias — the model makes overly simplistic assumptions. Overfitting is caused by high variance — the model is too sensitive to the training data. The bias-variance tradeoff means you can’t minimize both simultaneously; increasing model complexity reduces bias but increases variance. The goal is to find the right balance where both are acceptably low.
Q3. How do I know if my model is overfitting? The clearest signal is a large gap between your training accuracy and validation/test accuracy. If your training accuracy is 95%+ but your test accuracy is below 75%, that’s a red flag. You can also plot your training and validation loss curves — if training loss keeps decreasing while validation loss starts increasing, your model is overfitting.
Q4. What are the best techniques to fix overfitting in machine learning? The most effective techniques are: (1) Regularization — L1 (Lasso) or L2 (Ridge) to penalize model complexity, (2) Dropout for neural networks, (3) Early Stopping — halt training when validation loss stops improving, (4) Getting more training data or using data augmentation, and (5) Cross-validation to ensure your evaluation is robust.
Q5. Can a model overfit even with a large dataset? Yes, it can — though it’s less common. With an extremely complex model and not enough regularization, overfitting can still occur even with large datasets. The ratio of model complexity to dataset size matters more than the absolute dataset size alone.
🔗 Sources — Mixed List
Official Docs
- Underfitting vs Overfitting — sklearn
- Overfit and Underfit Guide — TensorFlow
- Ridge Regression — sklearn
- Dropout Layer — Keras
- Generalization — Google ML Crash Course
“Want to read more about AI and ML? Check out Beyond The Algorithm“